12-02-2025 Update:
chat.ciscohe.cc 现已升级为Open-WebUI。用户只需注册即可免费使用DeepSeek V3/R1 (deepseek-chat/deepseek-reasoner)。
支持:显示推理思考过程,保存记录,下载记录
不支持:联网搜索,使用DeepSeek以外的任何模型
***分割线***
在2023年3月,我host了一个域名chat.ciscohe.cc来让网友更方便得使用ChatGPT (GPT-3.5)来学习、写文章、做作业、写代码等。
后来随着时间的推进,因为国产AI的快速迭代进步和个人自身忙碌的原因没有时间解决国内访问CloseAI API等因素,我将chat.ciscohe.cc使用的模型切换到了DeepSeek V2的API,并也预告了国产LLM即将追赶上漂亮国的LLM(那时候DeepSeek还没火出圈)。
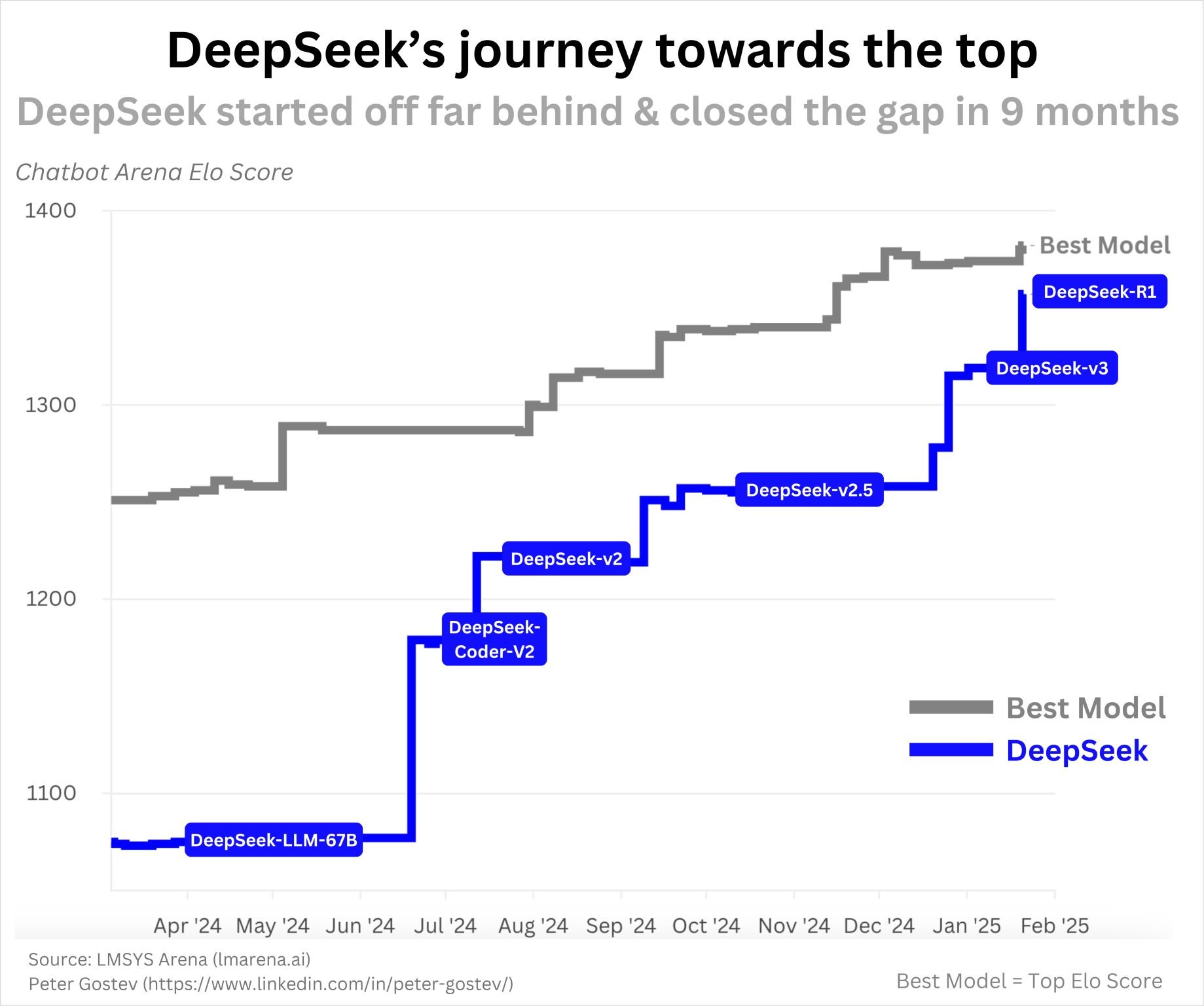
到24年12月,我觉得国产AI服务各方面已经好用过CloseAI,而且国产AI的官方客户端的综合体验也比我这个站点不仅体验好上万倍也完全免费(例如免费文档分析、CoT推理、图片识别等),性能也不会缩水(参考CloseAI的降智问题)。换句话说,用客户端总是免费,只是用API才收费。除此之外,用国产LLM的好处是快且符合本地化直觉,有手机客户端,知识也非常齐全(我个人而言)。
至此,chat.ciscohe.cc终可休欸。【老子可以拿充值的API做更加伟大的事情】
另一方面,国产LLM的追赶【卷】也有效大力鞭策故意将研发速度放缓和搞垄断整订阅制抬高价格(2000USD/MO SUBSCRIPTION WTF?)让人类不能公平地享受人工智能带来的进步、不思进取没有格局没有开源开放的某CloseAI,或者领着年薪还大于DeepSeek V3总训练成本的META高管们。
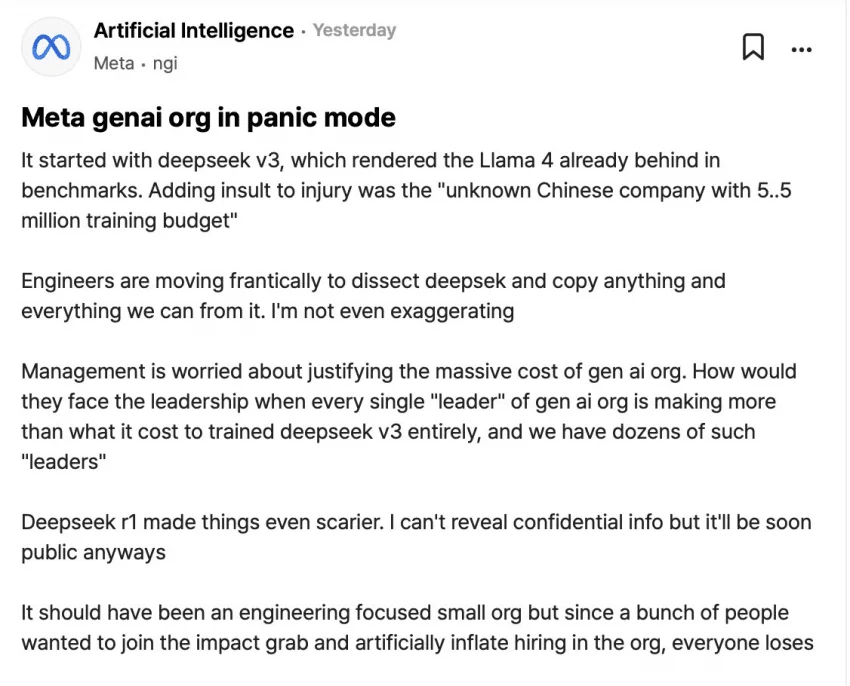
我个人对国产LLM排名如下:
T1战队【源神Open Source/大善人/价格屠龙少年】
- DeepSeek R1: 推理模型,看论文和网上的分析已经不输CloseAI的o1。
- DeepSeek V3: V2的迭代,现在我最常用的模型,我几乎每天都使用,API价格量大管饱。
- Qwen系列: 阿里巴巴的同义千问,在DeepSeek V3火出圈前它是开源第一。用过,也非常不错(家父喜爱)。
T2战队【追赶的佼佼者】
- 智谱清言(ChatGLM): 个人在2024年前半年都是用它,早期迭代最快最强的模型(它帮我做完了ROS2的FYP),后来因为网页版的反应越来越慢,使用体验不好(那时候缺钱?),且API略贵,近来也没怎么更新(感觉研究视频模型去了),遂弃用,转头DeepSeek,但整体依然很不错【小红书严选评论翻译服务商】。现在常在翻译领域见到它【DeepL:我没意见】。
- 豆包:评论都说好,听说字节跳动在疯狂烧钱升级,身边朋友也有用,体验应该很不错。最近出了Doubao-1.5-pro似乎也追赶上了4o。
- Kimi:评论也说好,最近推出(灰色测试)了Kimi 1.5推理模型,据闻能跟o1和DeepSeek R1打得有来有回,观望中。
- 华为盘古:【神秘的事物】
T3战队【边缘】
- 文言一心:百度看到就想骂,不多说了 (what_can_i_say.jpg)。
- 腾讯系列:不知名,无人问津。

总体而言,我现在手机里只装了智谱清言和DeepSeek最新出的客户端,API则用DeepSeek V3或者R1,可以解决我99%想要解决的问题。2025年,国产LLM正式追上CloseAI/Claude,有什么新的玩法,让我们拭目以待。
26-1-2025更新
听说DeepSeek继小红书后再次以国产软件登上各国App Store排行榜,希望歪果仁不要把它挤兑了,我还要用它来完成我的伟大理想QAQ【用不了就说不定要逃难到第三方托管例如SiliconCloud】。
28-1-2025更
哎,我的DeepSeek~


30-1-2025更
不是,我已经三天不能好好用API和网页版了,API管理platform也301维护几天了..
漂亮国(华尔街)的DDoS攻击可否止欸?SO WEAK AF AS HYPOCRITICAL LOSER

1-2-2025更
我本来不想在这个博客里讨论未来NVDA的股价,但是奈何刚说完第三方托管SiliconCloud后,SiliconCloud今天就正式宣布和菊花公司把DeepSeek模型成功部署在昇腾Ascend集算里..
这件事情其实意义重大,对我而言,如果这事儿流到外网,必定会再次翻起滔天巨浪,影响也必定会比一次的浪潮更汹涌!

简单点就是说:
- 上个星期的人都认为: 训练必须用达哥大量的卡,推理也要用达哥大量的卡才能推动超大模型
- 这个礼拜的人都开始认为:训练但是不需用达哥大量的卡(第一次逻辑转变),推理依然要用达哥大量的卡才能推动超大模型
- 或许下个星期的人会开始认为:训练但是不需用达哥大量的卡,推理但是不需用达哥的卡也能推动超大模型(即将到来的第二次逻辑转变)
当然,这些信息也是今天2025年2月1号才宣告,我也第一时间兴奋地写了出来,至于什么时候传导到西方传媒,西方的科技界,西方的金融界,参考V3和R1,一个月之内吧~【这就是信息差】
整个AI大模型的逻辑才一个月内发生翻天覆地的变化,各位,如果你持有NVDA的股份,还是早点放了吧。

当然,网上还有一些呆瓜说,DS其实不是制造了未来更多买推理卡的需求吗?NVDA还会涨回去的!
我只想说,在训练卡的角度来看,LLM训练的需求端依然需要达哥,但是LLM推理的需求端才是最大的(用模型),但是已经不再必须是达哥,达哥不再是唯一。
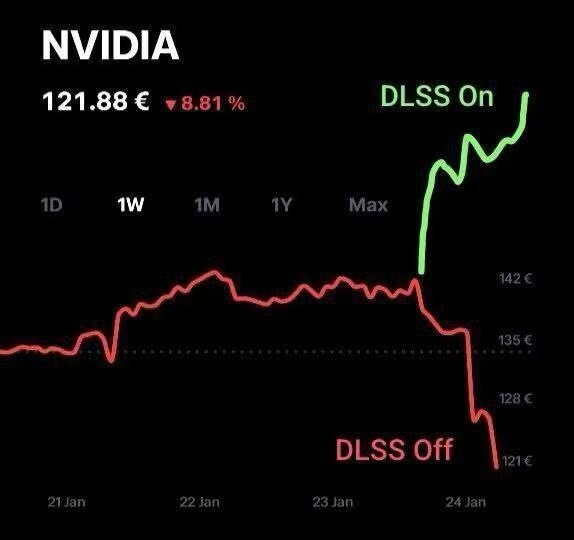
当然有人依然看不懂,因为他们只想买了股票这个资产等着升值,或者明知道但是装傻怂恿大家上车,自己偷偷放掉,非蠢即坏哦。【关键词:Ascend 910, MindIE inference, Huawei Cloud, SiliconCloud, SiliconFlow】
好的,回到正题,我刚把DeepSeek的API换到SiliconCloud,先暂移民。这几天都不能好好流畅用官方API和网页端写Godot研究游戏设计,我哭死。
继续使用我的chat.ciscohe.cc站点
当然,如果你依然需要使用我的站点来访问DeepSeek V3 AI服务,那就点这里吧 (Open WebUI)。
***
这才2025年第一个月,就已经发生这么多魔幻且回旋镖的事情:六代机,小红书,DeepSeek,实在精彩。
end.