设想
今天在Github见到了一个有趣的项目,名叫chatchat-space/Langchain-Chatchat: Langchain-Chatchat。是一个将Langchain应用做大做强的可以让非计算机科学系人类简易部署的本地知识库问答(常见商业应用:ChatDoc, ChatPDF)。
现今咱们的国家的互联网企业或已孵化项目推出了琳琅满目又十分之高效率强大的大模型例如智谱清言ChatGLM, QWen (阿里巴巴-通义千问),和甚至新的超低价卷王DeepSeek V2等暴打CloseAI GPT-3.5甚至齐平GPT-4,为此笔者也理所当然老早从CloseAI的垃圾3.5转用ChatGLM-4数月(什么你说国内大模型敏感关键字?咱们用人工智能来虚心求学到底什么terminology会涉及到政治危险词语?)。幸运的是,国内的这些大模型也提供了非常强大的免费长文档知识库问答的功能,如果不是这样,我还用着万恶的资本主义8美金一个月的ChatDoc来帮我看文献(现在不用看了终于)。
不过,如果可以自己部署长文档知识库问答,也是一件挺有趣的事情对吧?
幸有两件事促成:
1. 长文档知识库问答需要Embedding模型和LLM大模型,因为我只有两张可怜的8GB的RTX 2080,我觉得我并没有能力部署强大的大模型,部署小模型也未必有好效果(费电),而且我也希望是部署在我的迷你服务器长期运行。幸亏的是,这个本地知识库的问答应用支持直接用网上的API来应用 LLM 与 Embedding 模型来分析文档。
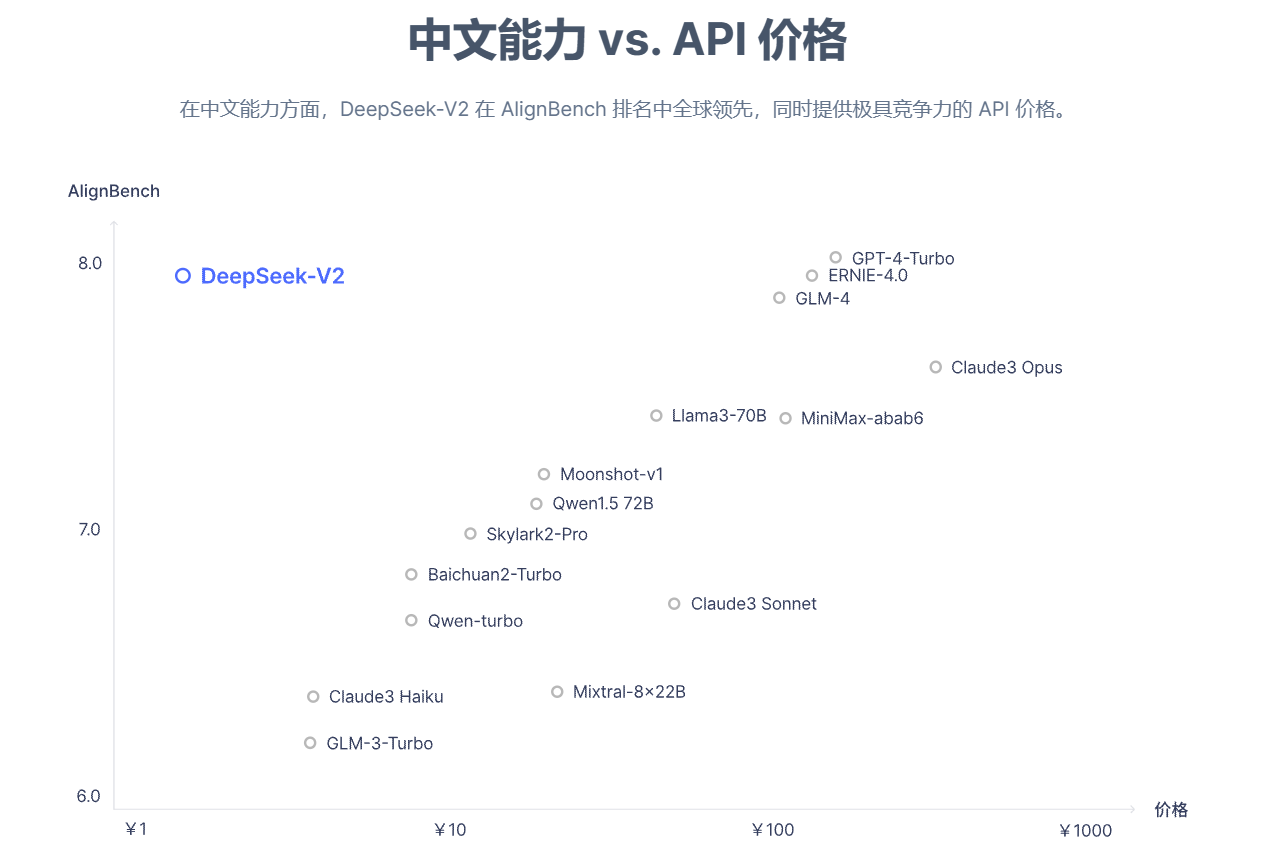
2. 如刚才所言,前几天国内幻方(运用AI来做量化金融的公司)推出了DeepSeek V2,宣称智能水平跟GPT-4有来回,除了审核较为严谨(这没问题,用来分析长文档不会碍事)。但是API的价格出奇便宜,3 RMB做到一百万token输入/输出,太便宜了会不会,这样子的自行单车干嘛还要用CloseAI?根据官方文档,DeepSeek API与CloseAI API兼容,所以我们LLM大模型就可以用这个替代其他昂贵的大模型。


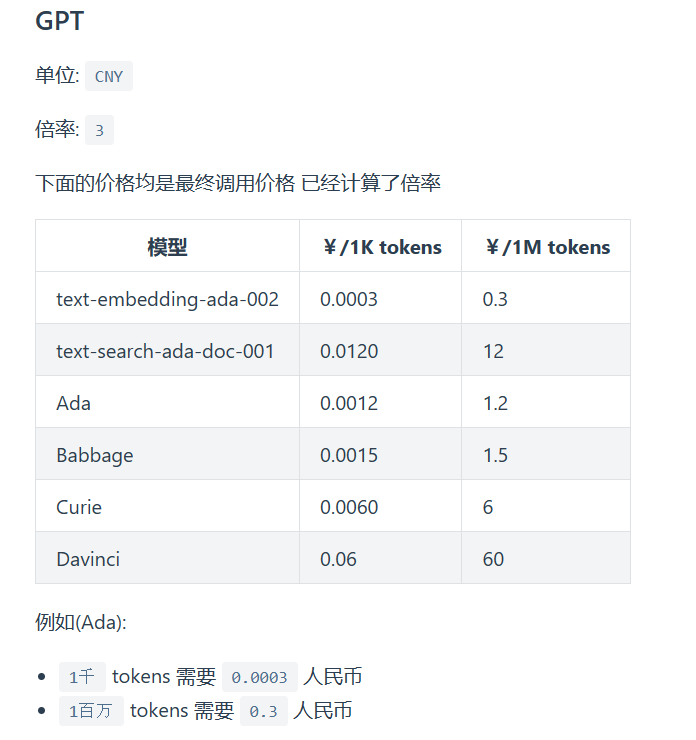
至于Embedding模型,我们用回CloseAI吧,CloseAI的Embedding模型并不贵。至于去哪里拿API,当然还是用我熟悉的供应商OpenAI-SB的中转服务了,他家的GPT-3.5超级便宜(可惜现在真的觉得3.5不够胜任了)。
所以这个项目的组合可以是:
LLM:deepseek-chat
Embedding:text-embedding-ada-002
OK,那我们开始实践。
实践
Step 1:首先我在我的Ubuntu 22.04家服务器git clone下这个项目:
Step 2:根据官方的说明书,咱们用最轻模式本地部署方案,即是 LLM 与 Embedding 模型都是用在线API实现,而不是使用自己运行的模型。
所以,我们安装简易过的依赖包:
Step 4: 编辑API,这里使用我的One-API
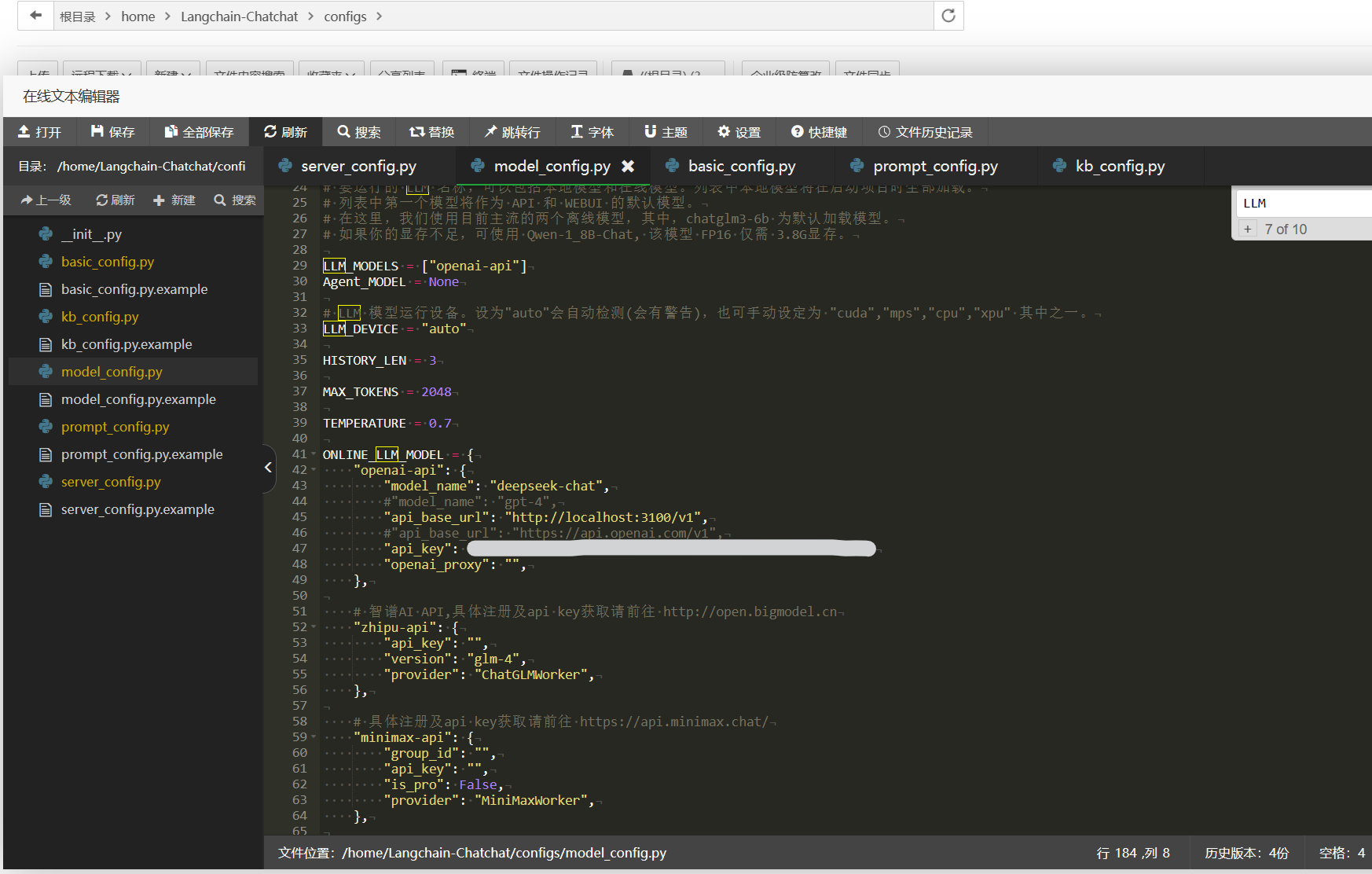
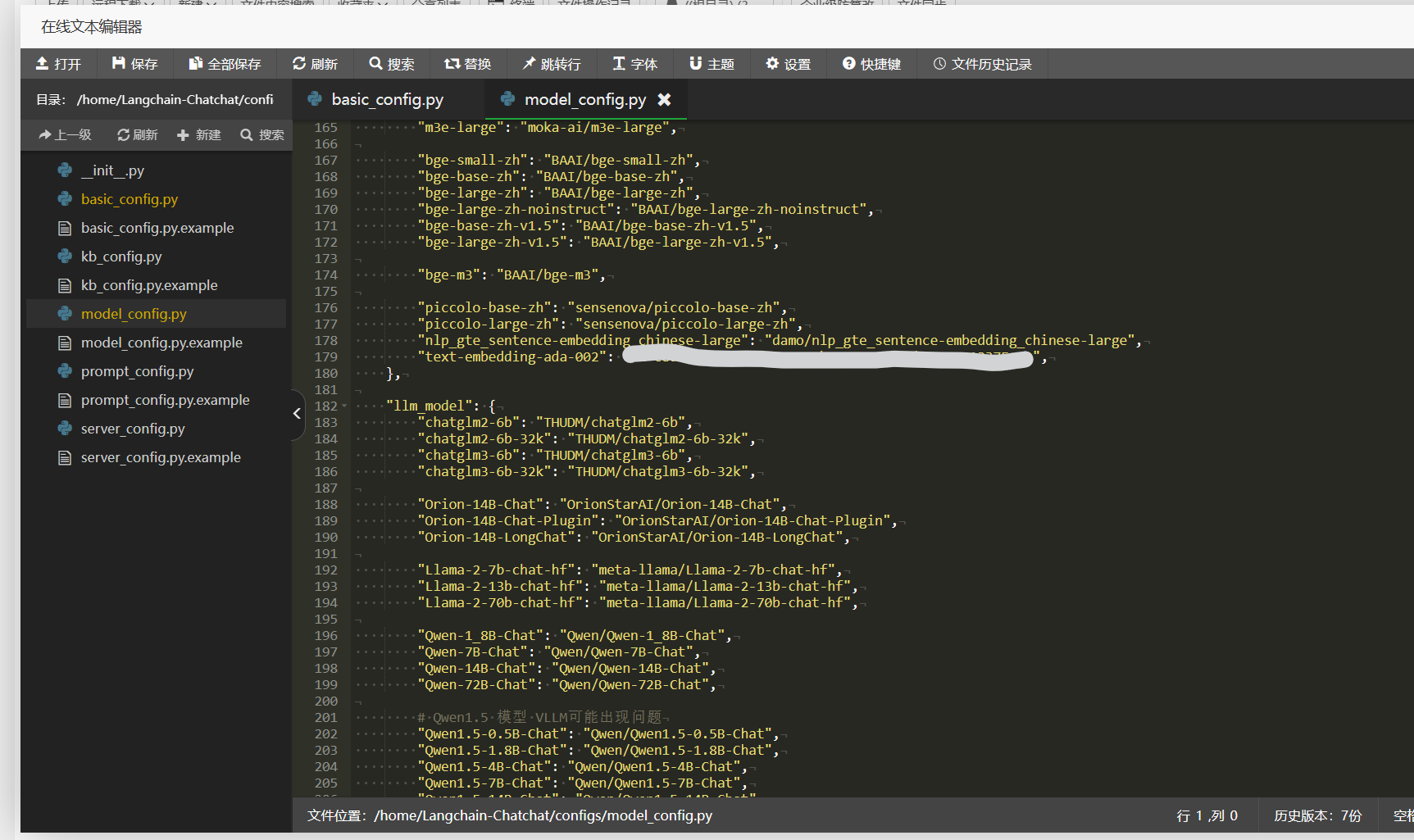
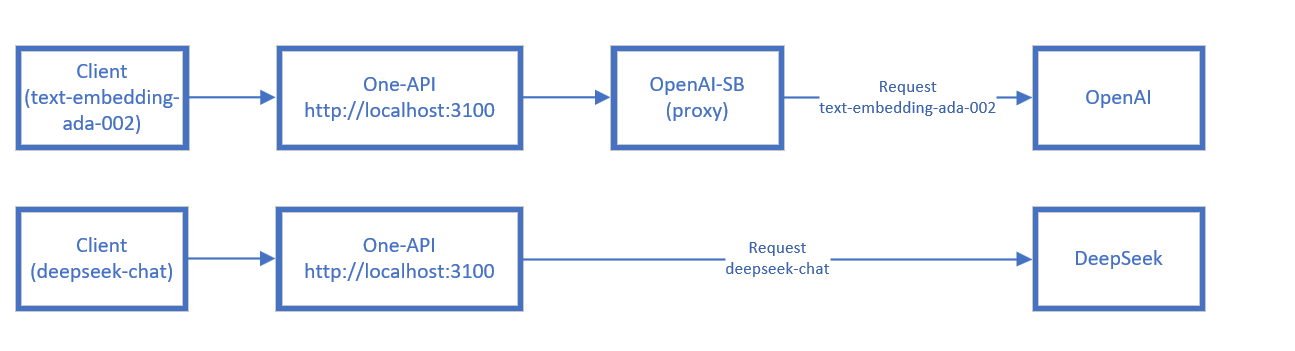
因为我发现这个项目的配置有点麻烦,如果我直接把CloseAI的base_url切换成deepseek的api,那么当使用Embedding模型的时候也自动访问DeepSeek的URL而不是容许我改成请求OpenAI-SB,所以这里我就用One-API。One-API是什么这里就不多讲述了,去年玩Pandora项目的时候搭建的一个可以让让不同厂商的大模型API的统一接口管理 & 分发系统。就好比只要我request图中的localhost:3100/v1的API地址并且在POST中附上指定的模型名字和我的One-API key,One-API就会自动帮我中转/request不同的AI模型的API网站with我设定好的API key。

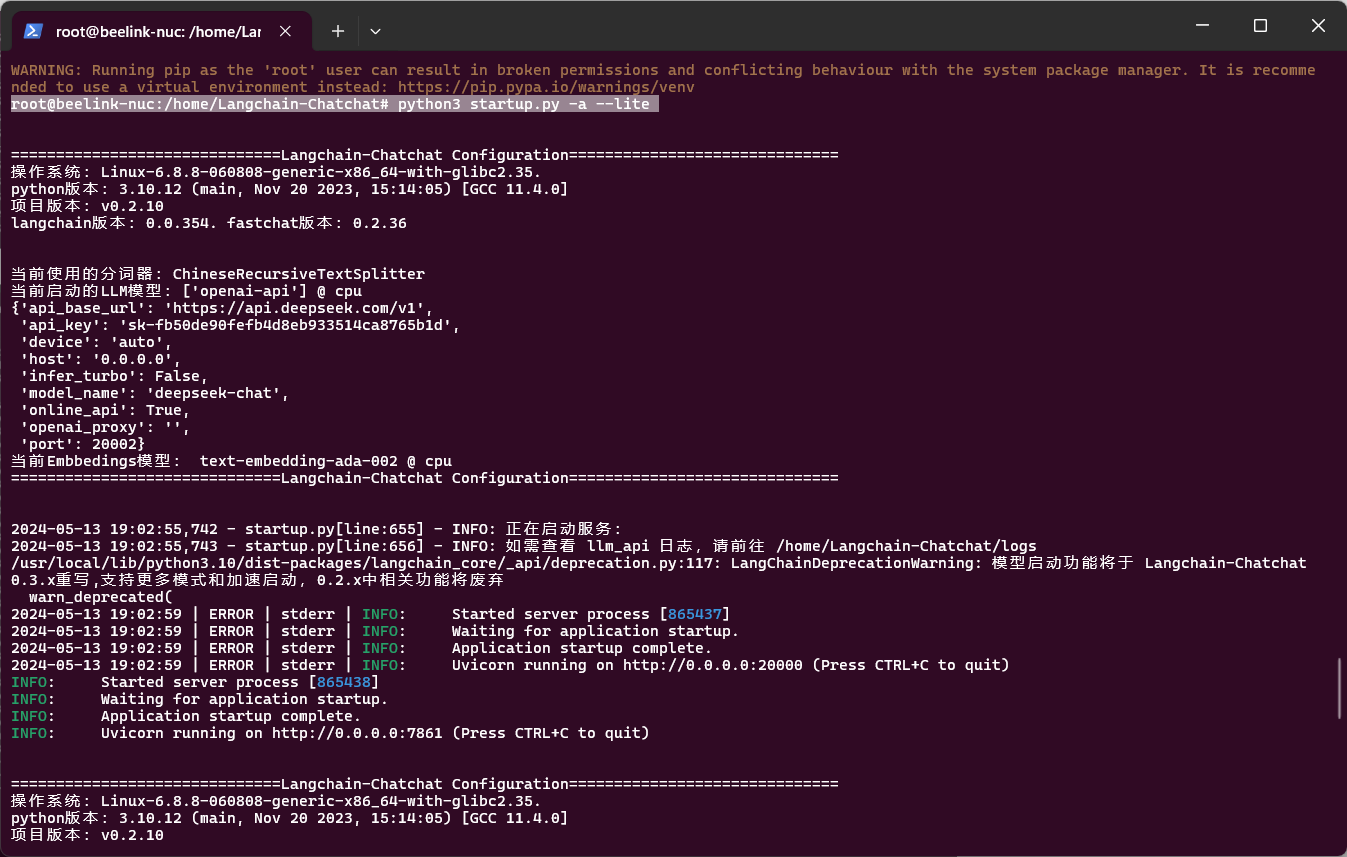
Step 5: Run
然后发现事情肯定没有想象中的简单:
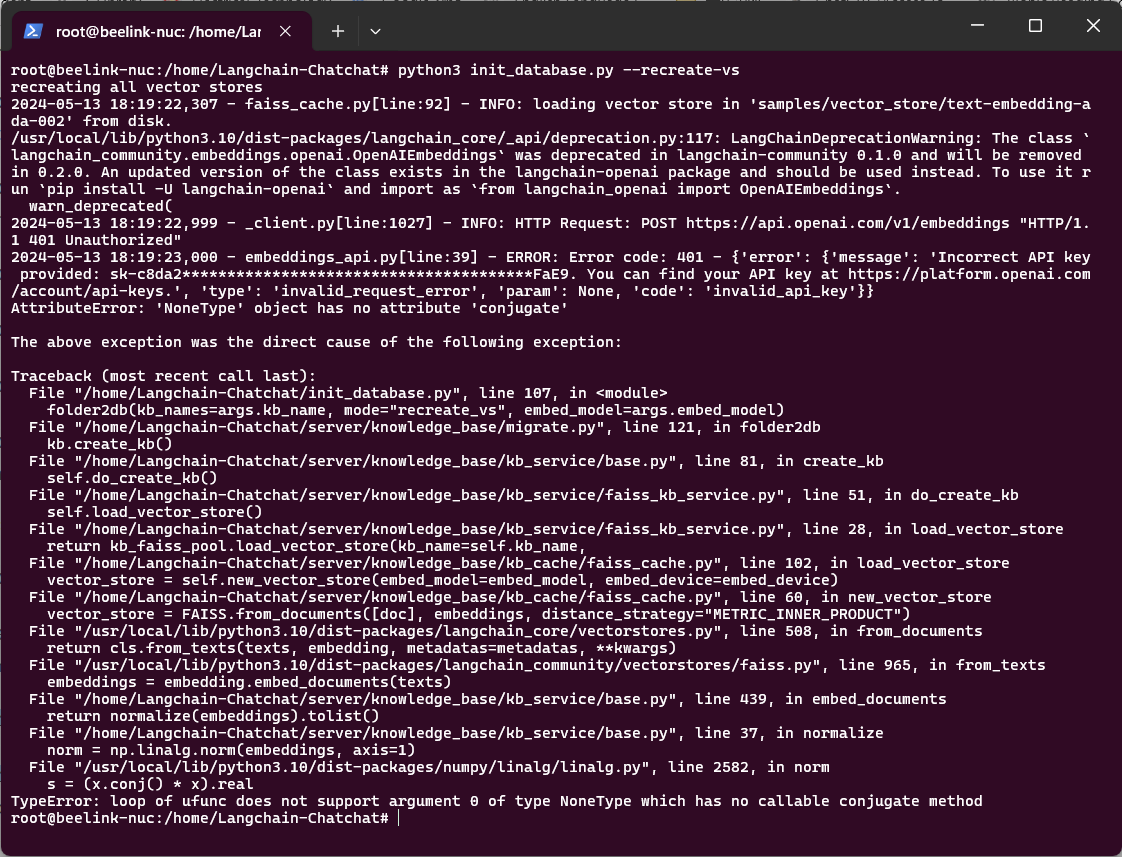
我发现如果用text-embedding-ada-002模型则会调用OpenAIEmbeddings这个实例(还是method?OOP编程懂了又不懂)。但是这个项目并没有提供Embedding模型的base_url给我修改,反而刚才的LLM模型给我修改成One-API的URL (http://localhost:3100/v1)。
好在网上有教程:
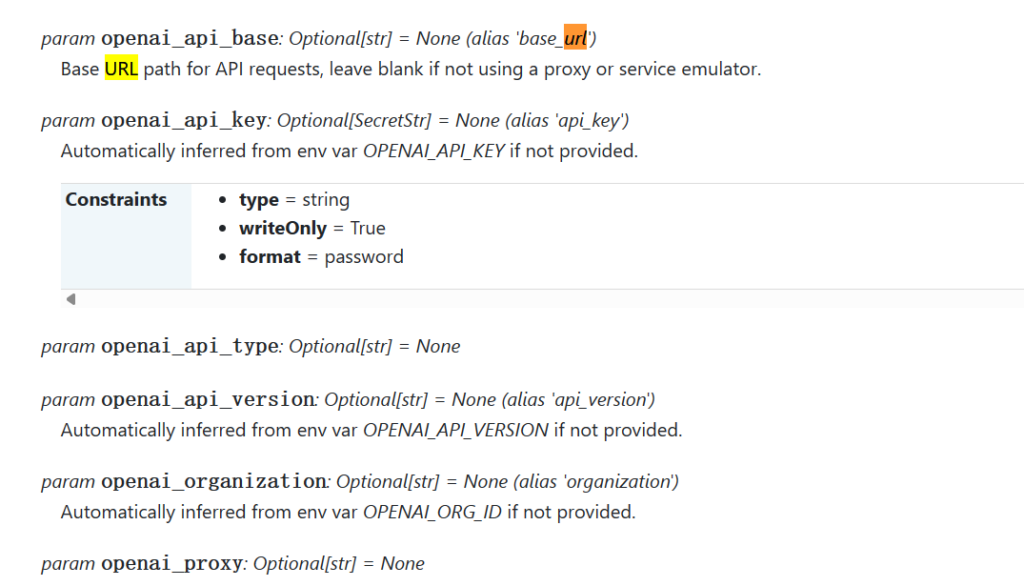
那就在GitHub项目里搜索一下这个项目哪里用了OpenAIEmbeddings:
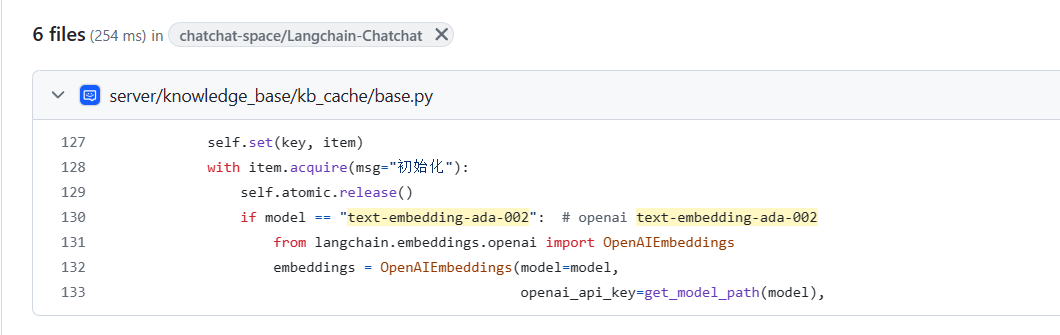
好的,那就直接在server/knowledge_base/kb_cache/base.py这个位置中的OpenAIEmbeddings添加openai_api_base这个parameter,让OpenAIEmbeddings不熬直接访问CloseAI官方API,而是先走我的One-API中转一次先(其实也可以直接中转到OpenAI-SB,都一样不过还是统一出入口好了)。
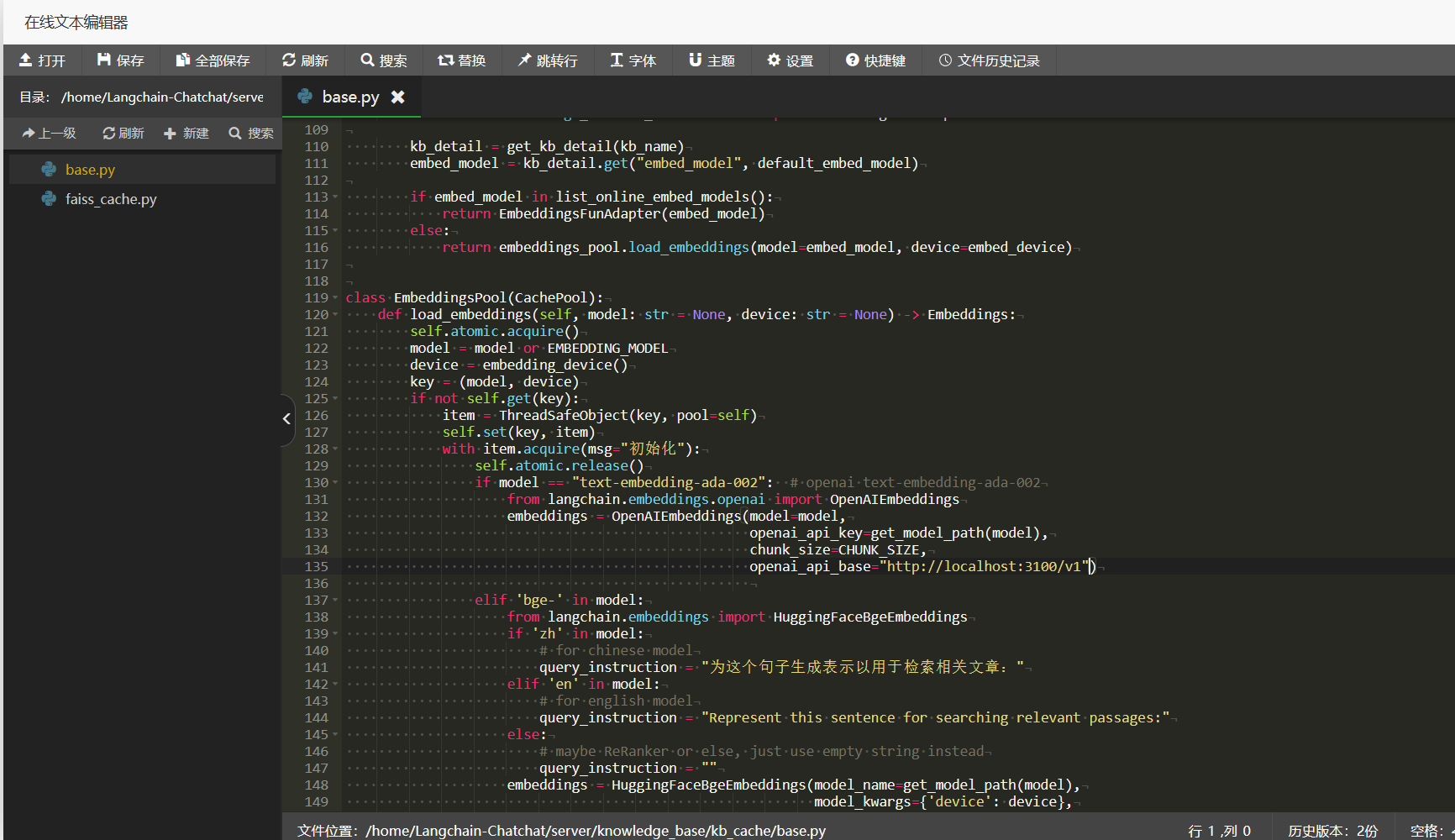
可以正常使用到text-embedding-ada-002模型后,这次数据库也终于成功建立起来了:
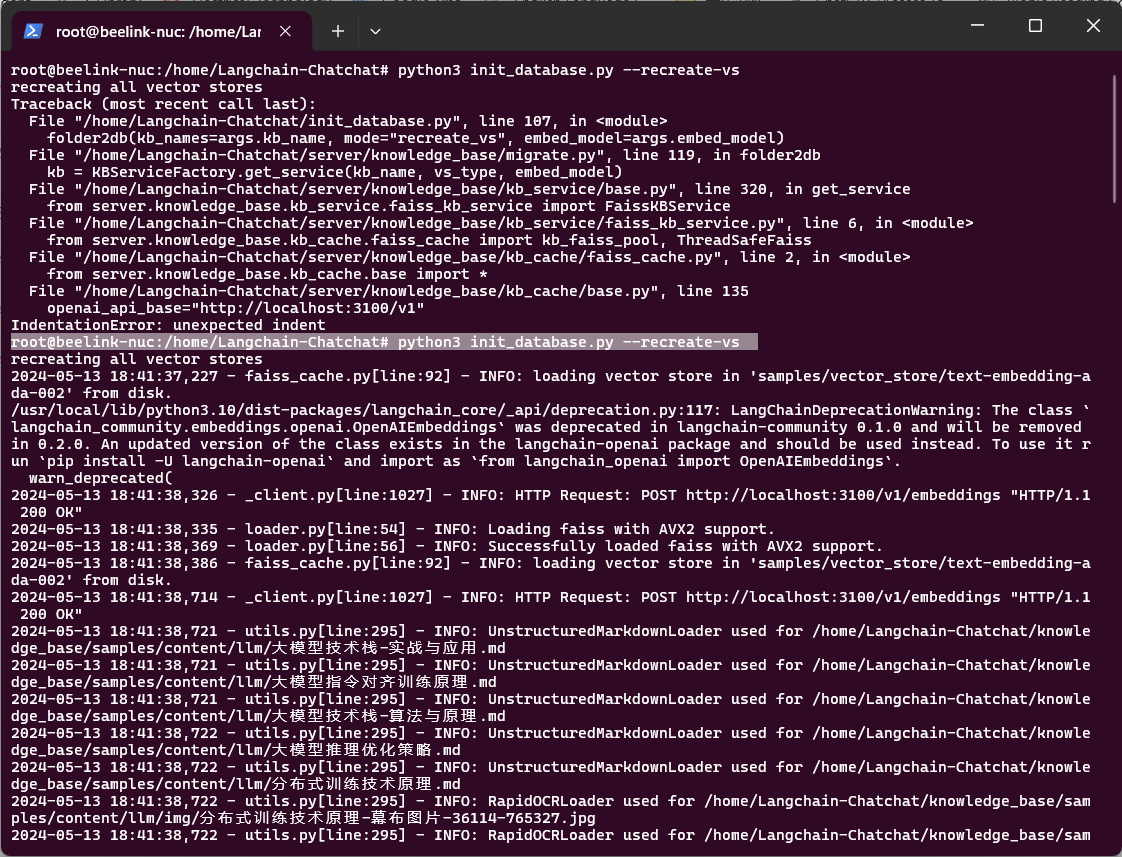
咱们启动:
反向代理一下我任意一个网站,例如auto.ciscohe.cc:
可见已经运行起来了。
评测
我试着上传了一份我去年写的一份Sociology的essay喂给Embedding模型(text-embedding-ada-002)然后让大模型LLM(deepseek-chat)回答我PDF中的问题:
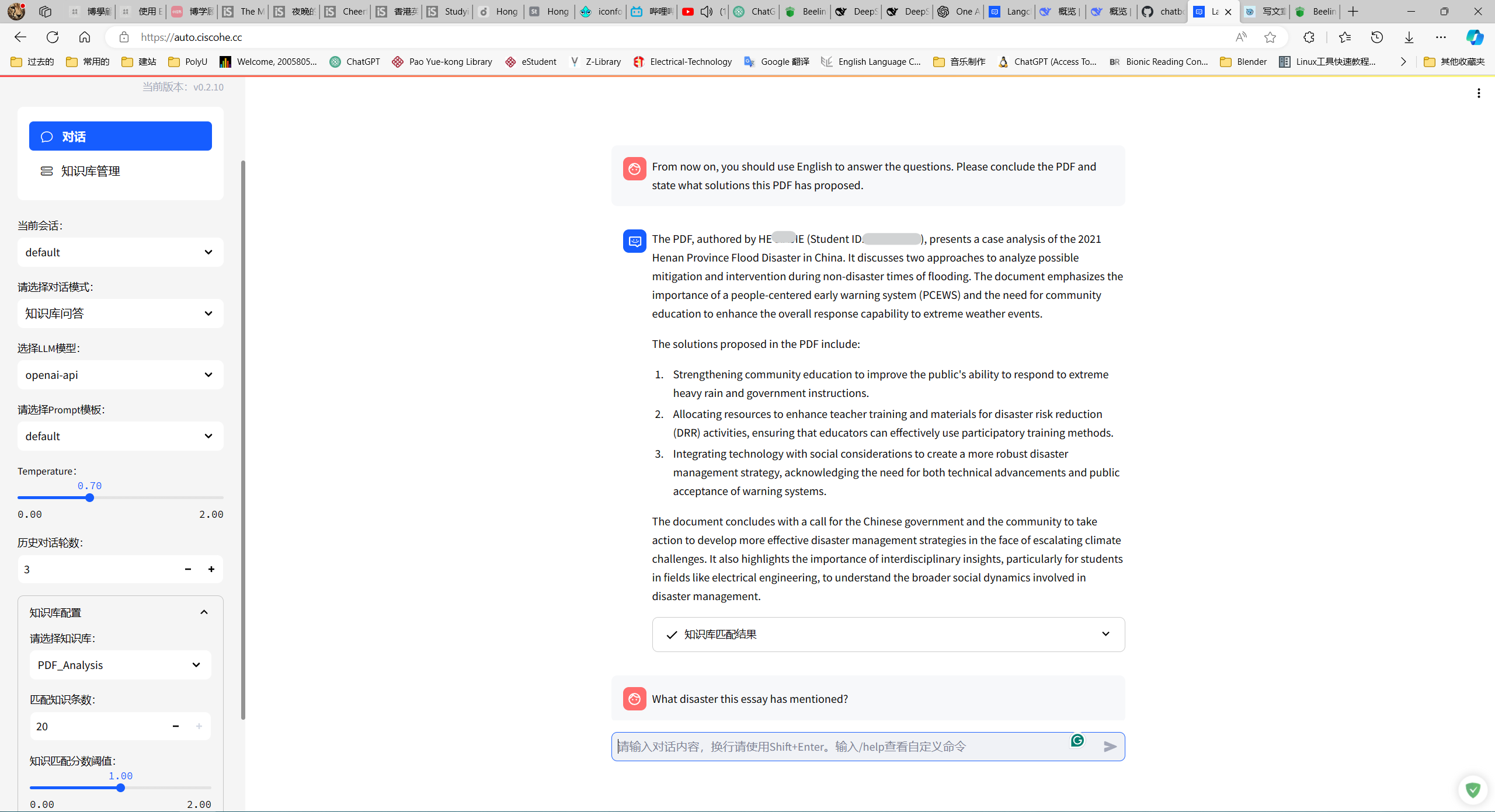
整体来看还是不错的,不过总是自动补全为中文,不知道怎么设置prompting呢?
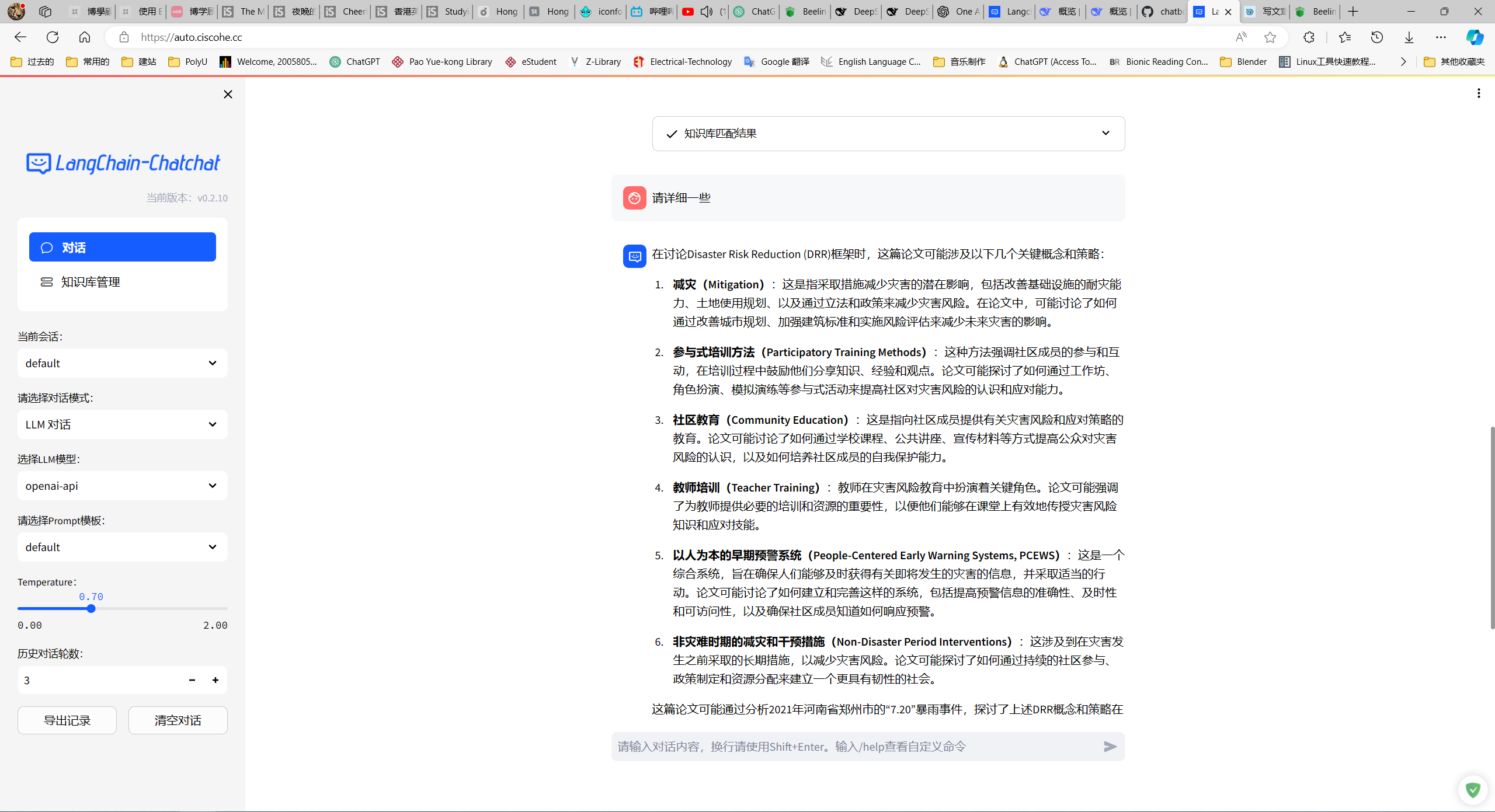
还是可以的,可以总结到我文中proposed的solutions。
总结
这种AI project的搭建其实是讲怎么把模型的API正确的识别并让整个系统启动,还有就是下载libraries可能会遇到奇怪的问题,不过这些都容易解决。
整个系统实测下来,我觉得还是不够商业的ChatDoc或者ChatPDF那些做的成熟,不过胜在免费开源,而且可以使用非常低成本的国产大模型例如DeepSeek V2配合CloseAI成熟的Embeeding模型使用,可能一万次的问答都不过3元人民币。因此这是成熟能够在商业上做成:把不同的技术文档融合在一起,然后整一个自动客服机器人,客户只需要询问它就可以自动根据文档内容回答正确的专业知识,提升生产效率。因此,知识库问答是未来人工智能其中一个非常重要的一个发展需求。
试想想,淘宝/阿里巴巴外贸(AliExpress)完全可以制作一个自家通义千问驱动的客服,它可以自动识别商家的产品介绍和规格参数,然后做外贸的时候,不同国家的人就算用不同的语言询问机器人客服,机器人客服也可以清楚表达产品的功能/定位/满足的需求,这从做外贸生意的角度来说打通了国与国沟通的屏障,同时也大大减少了人力培训,就可以即时满足B2B/B2C的咨询或买卖需求。我也相信阿里巴巴正在朝这方向做,这可以是他打败拼夕夕/狗东的第二路径。
功能上大致是如此,有空再研究一下可以怎么玩。
End.