本来后台用 mufeng510/Free-ChatGPT-API: 基于pandora的ChatGPT API,实现了pool token的自动更新 (github.com)的Python脚本好好的,直到…
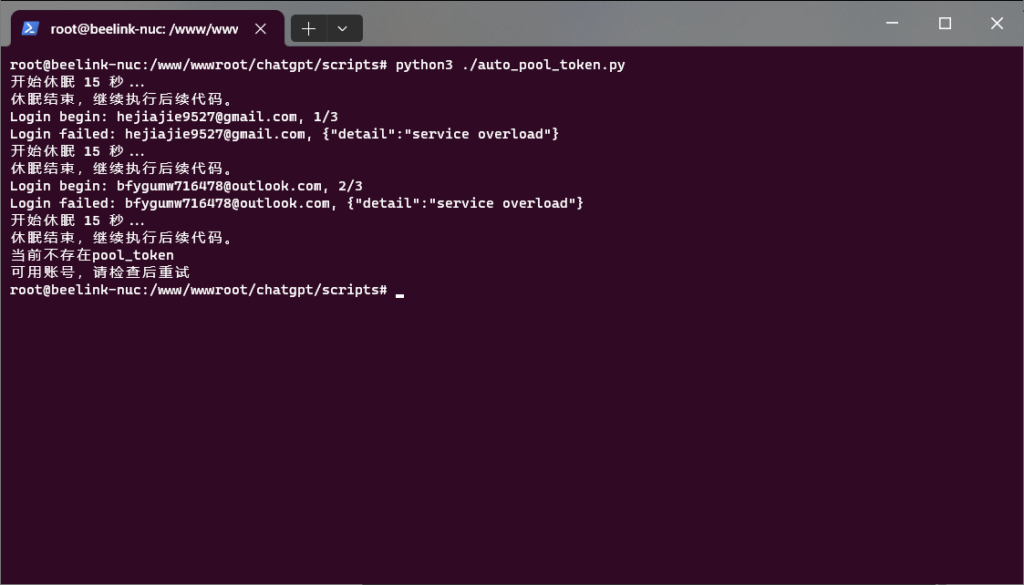
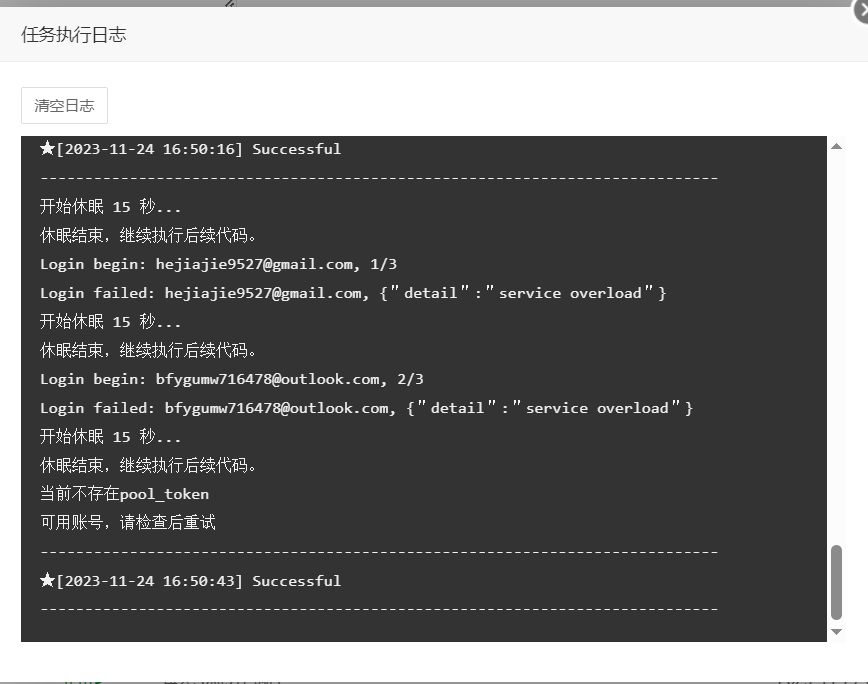
嗯?
欸
所以用账号和密码自动续期免费逆向API的服务失效了:
原来的Python续期脚本:账号密码—>FakeOpen API获取Access Token (这里失效了) —>获取新的Share Token (失败)—>更新Pool Token失败
不过,也还是有办法的,在FakeOpen登陆网页获取Session Token—>Python脚本:Session Token—>FakeOpen API获取Access Token—>获取新的Share Token—>更新Pool Token
好的,那就… 写个新的Python续期脚本吧!(也借鉴了一下原作者的脚本,谢谢他教会我怎么用Python写POST Request和JSON解析和读写文件保存)
首先看看原本的Python脚本(mufeng510/Free-ChatGPT-API: 基于pandora的ChatGPT API,实现了pool token的自动更新 (github.com)):
# -*- coding: utf-8 -*-
import requests
import random
import string
import time
import re
from os import path
from pandora.openai.auth import Auth0
def run():
unique_name = generate_random_string(10)
expires_in = 0
current_dir = path.dirname(path.abspath(__file__))
credentials_file = path.join(current_dir, 'credentials.txt')
tokens_file = path.join(current_dir, 'tokens.txt')
share_tokens_file = path.join(current_dir, 'share_tokens.txt')
pool_token_file = path.join(current_dir, 'pool_token.txt')
# 生成 share token。
with open(credentials_file, 'r', encoding='utf-8') as f:
credentials = f.read().split('\n')
credentials = [credential.split(',', 1) for credential in credentials]
count = 0
token_keys = []
for credential in credentials:
# 接口有限流。
sleep_seconds = 15
print(f"开始休眠 {sleep_seconds} 秒...")
time.sleep(sleep_seconds)
print("休眠结束,继续执行后续代码。")
progress = '{}/{}'.format(credentials.index(credential) + 1, len(credentials))
if not credential or len(credential) != 2:
continue
count += 1
username, password = credential[0].strip(), credential[1].strip()
print('Login begin: {}, {}'.format(username, progress))
token_info = {
'token': 'None',
'share_token': 'None',
}
token_keys.append(token_info)
try:
token_info['token'] = Auth0(username, password).auth(False)
print('Login success: {}, {}'.format(username, progress))
except Exception as e:
err_str = str(e).replace('\n', '').replace('\r', '').strip()
print('Login failed: {}, {}'.format(username, err_str))
token_info['token'] = err_str
continue
data = {
'unique_name': unique_name,
'access_token': token_info['token'],
'expires_in': expires_in,
}
resp = requests.post('https://ai.fakeopen.com/token/register', data=data)
if resp.status_code == 200:
token_info['share_token'] = resp.json()['token_key']
print('share token: {}'.format(token_info['share_token']))
else:
err_str = resp.text.replace('\n', '').replace('\r', '').strip()
print('share token failed: {}'.format(err_str))
token_info['share_token'] = err_str
continue
with open(tokens_file, 'w', encoding='utf-8') as f:
for token_info in token_keys:
f.write('{}\n'.format(token_info['token']))
with open(share_tokens_file, 'w', encoding='utf-8') as f:
for token_info in token_keys:
f.write('{}\n'.format(token_info['share_token']))
# 生成 pool token, 如果已有pool token则更新, 没有则新建。
with open(pool_token_file, 'r', encoding='utf-8') as f:
pool_token = f.read()
if(len(pool_token) == 0):
print("当前不存在pool_token")
else:
if(re.compile(r'pk-[0-9a-zA-Z_\-]{43}').match(pool_token)):
print('已存在: pool token: {}'.format(pool_token))
else:
print('pool token: 格式不正确,将重新生成')
pool_token = ""
# 从 token_keys 列表中筛选出有效数据
filtered_tokens = [token_info['share_token'] for token_info in token_keys if re.compile(r'fk-[0-9a-zA-Z_\-]{43}').match(token_info['share_token'])]
with open(pool_token_file, 'w', encoding='utf-8') as f:
if len(filtered_tokens)==0:
# 如果没有可用账号,则使用公共pool。
print('可用账号,请检查后重试')
else:
data = {
'share_tokens': '\n'.join(filtered_tokens),
'pool_token': pool_token
}
resp = requests.post('https://ai.fakeopen.com/pool/update', data=data)
if resp.status_code == 200:
result = resp.json()
print('pool token 更新结果: count:{} pool_token:{}'.format(result['count'],result['pool_token']))
pool_token = result['pool_token']
f.write('{}'.format(pool_token))
else:
print('pool token 更新失败')
f.close()
def generate_random_string(length):
letters = string.ascii_letters
random_string = ''.join(random.choice(letters) for _ in range(length))
return random_string
if __name__ == '__main__':
run()好像很复杂,但是不要紧,我最近找到了FakeOpen的文档!整体跟着它的POST接口请求然后JSON解析下就可以了。例如发Session Token获取Access Token的POST:
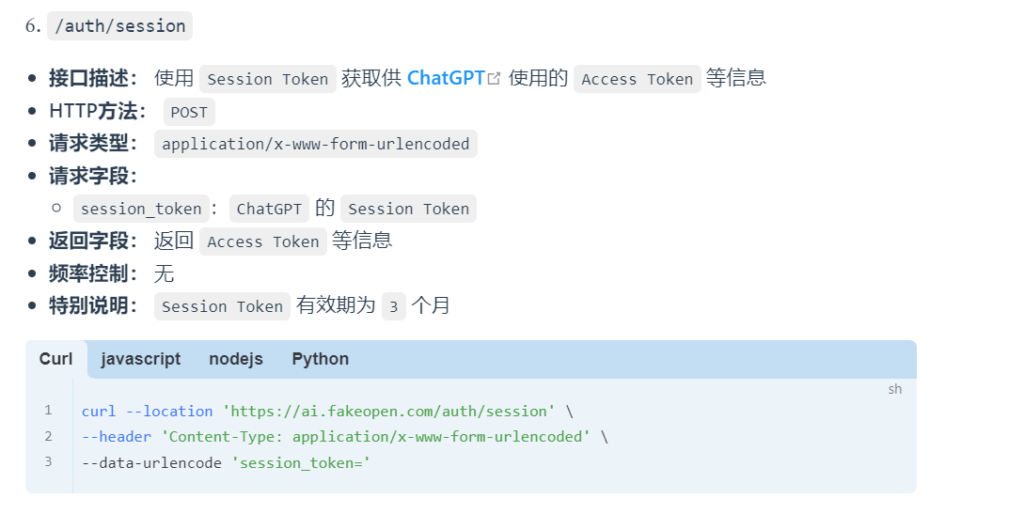
官方文档:Fakeopen API 文档 | FakeOpen Doc
好的,那就趁Professor在review过去12 weeks教了什么让我憔悴的内容的时候写出来吧~
(开源)
# -*- coding: utf-8 -*-
import requests
import json
import random
import string
import time
import re
import os
def generate_random_string(length):
letters = string.ascii_letters
random_string = ''.join(random.choice(letters) for _ in range(length))
return random_string
current_dir = os.path.dirname(os.path.abspath(__file__))
session_file_path = os.path.join(current_dir, 'session.txt')
share_tokens_file = os.path.join(current_dir, 'share_tokens.txt')
pool_token_file = os.path.join(current_dir, 'pool_token.txt')
# 读取 session_keys
with open(session_file_path, 'r', encoding='utf-8') as session_file:
session_keys_str = session_file.read().strip()
# 检查 session_keys_str 是否存在
if not session_keys_str:
print("Error: Session keys are missing in session.txt")
else:
# 用逗号分隔并去除两侧空白字符
session_keys = [key.strip() for key in session_keys_str.split(',')]
# 输出分离后的 session_keys (For debugginh
#print('Key1:\t', session_keys[0])
#print('Key2:\t', session_keys[1])
#Set up headers for POST (according to FakeOpen Document)
headers = {
'Content-Type': 'application/x-www-form-urlencoded'
}
#Counting number of loops
count = 0
#Create share_tokens list to store Share Tokens as elements
share_tokens = []
#For Loop: If n Session keys are found in session.txt, then n times of exections are proceeded to register n Share Tokens
for i in range(len(session_keys)):
#Loop + 1
count += 1
#1. Use POST to fetch access token by session token (Session Token-->Access Token)
playload_access_token = {
'session_token': session_keys[i]
}
response_access_token = requests.post('https://ai.fakeopen.com/auth/session', headers=headers , data=playload_access_token)
#200 OK?
if response_access_token.status_code == 200:
print('Get Access Token ({}/{})'.format(count,len(session_keys)))
else:
err_str = response_access_token.text.replace('\n', '').replace('\r', '').strip()
print('Failed to get Access Token: {}'.format(err_str))
continue
#Debug response_access_token
#print(response_access_token.text)
list_access_token = json.loads(response_access_token.text)
access_token = list_access_token['access_token']
#No need expires_in anymore
#expires_in = list_access_token['expires_in']
#Function for generating unique token names
unique_name = generate_random_string(10)
#2. Use POST to fetch share token by access token (Access Token-->Share Token)
playload_share_tokens = {
'unique_name': unique_name,
'access_token': access_token
}
response_share_tokens = requests.post('https://ai.fakeopen.com/token/register', headers=headers, data=playload_share_tokens)
#200 OK?
if response_share_tokens.status_code == 200:
#I put all remaining code here
list_share_tokens = json.loads(response_share_tokens.text)
print('Get Share token:{} ({}/{})'.format(list_share_tokens['token_key'],count,len(session_keys)))
share_tokens.append(list_share_tokens['token_key'])
else:
err_str = response_share_tokens.text.replace('\n', '').replace('\r', '').strip()
print('Failed to get Share Token: {}'.format(err_str))
continue
#End of for-loop
#Write string to txt
with open(share_tokens_file, 'w', encoding='utf-8') as f:
#Write share_tokens[0], share_tokens[1], share_tokens[2], ... share_tokens[n-1] elements of Share Tokens into share_tokens.txt
for token in share_tokens:
f.write(f"{token}\n") #写入到share_tokens.txt
print('写入share tokens到share_tokens.txt完成')
# 生成 pool token, 如果已有pool token则更新, 没有则新建。
with open(pool_token_file, 'r', encoding='utf-8') as f:
pool_token = f.read()
if(len(pool_token) == 0):
print("当前不存在pool_token")
else:
if(re.compile(r'pk-[0-9a-zA-Z_\-]{43}').match(pool_token)):
print('Already Exist: pool token: {}'.format(pool_token))
else:
print('pool token: 格式不正确,将重新生成')
pool_token = ""
#How to generate a pool token? Good question. If there is no pool token in pool_token.txt, you can leave it blank. After updating (POST) to the FakeOpen server, the server will generate a new pool token which will be saved in pool_token.txt.
#3. Use POST to UPDATE pool token by share tokens (Share Token-->Pool Token)
playload_pool = {
'share_tokens': '\n'.join(share_tokens), #According to FakeOpen Document
'pool_token': pool_token
#This is the pool token which does not change. This token can store bunch of share tokens. Regular Update pool token is necessary.
}
response_pool = requests.post('https://ai.fakeopen.com/pool/update', data=playload_pool)
list_pool_token = json.loads(response_pool.text)
#Display Pool Token (Debugging)
#print('Pool token: ',list_pool_token['pool_token'])
#Write string to txt
with open(pool_token_file, 'w', encoding='utf-8') as f:
f.write(f"{list_pool_token['pool_token']}\n") #写入到share_tokens.txt
print('写入pool token到pool_token.txt完成')
很好,跑一下看看:
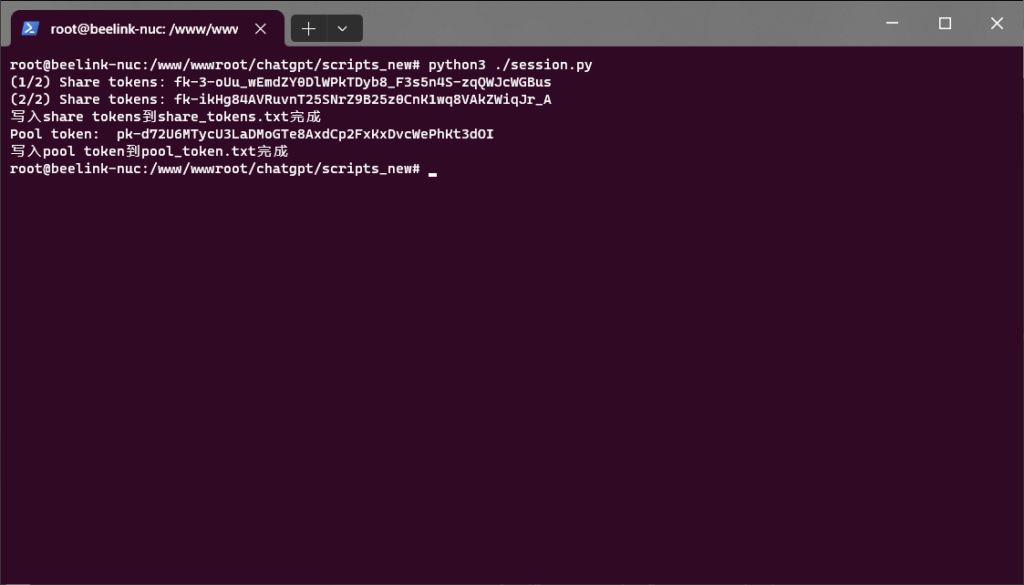
很好,又有API key可以用了,丢去后台:
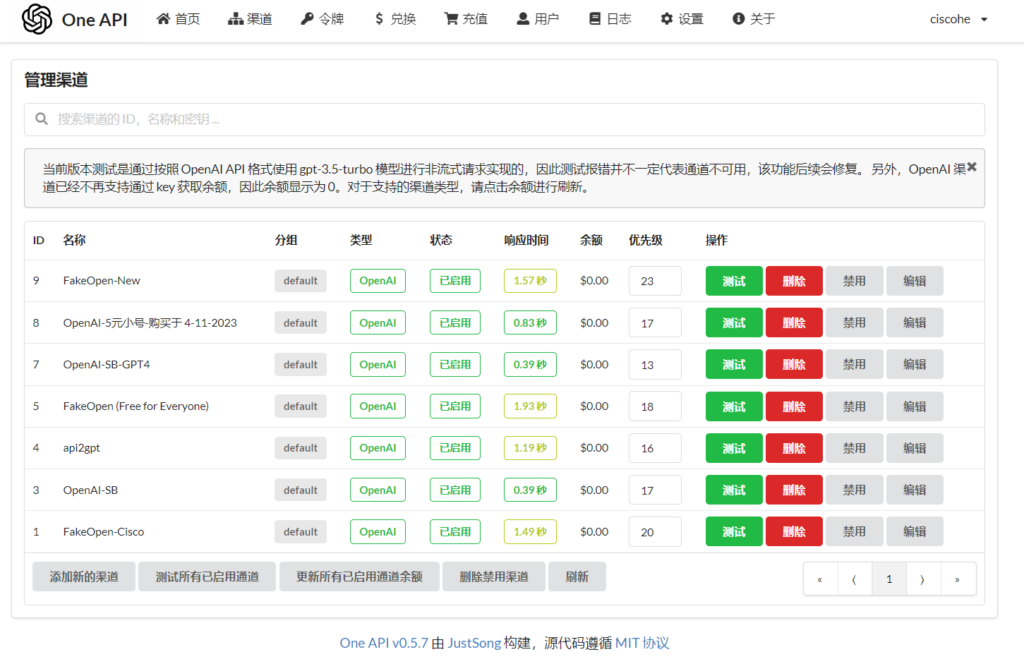
ChatGPT,启动!
(至于详细的使用教程,有空再讲解吧,懂Python代码的也知道我怎么做了(我的代码程度只是中学生水平),不过有一项注意:session.txt里面存储的session token如果有多余一个的话请用英文逗号分开。P.S. Session Token也挺好,三个月才过期,比Access Token只有十天的期限长太多了。)
其他ChatGPT (ciscohe.cc) 历史更新: chat.ciscohe.cc/update/
End.
Last Edited at 0015hrs on 28/11/2023